“I think, therefore I am”
We finally have a Large Language Model that beats the average human IQ. Claude-3, released last week by Anthropic, has been received extremely well, and it good enough that it beats all others including GPT-4.

Now, this is impressive. Anthropic themselves released the below graphic.
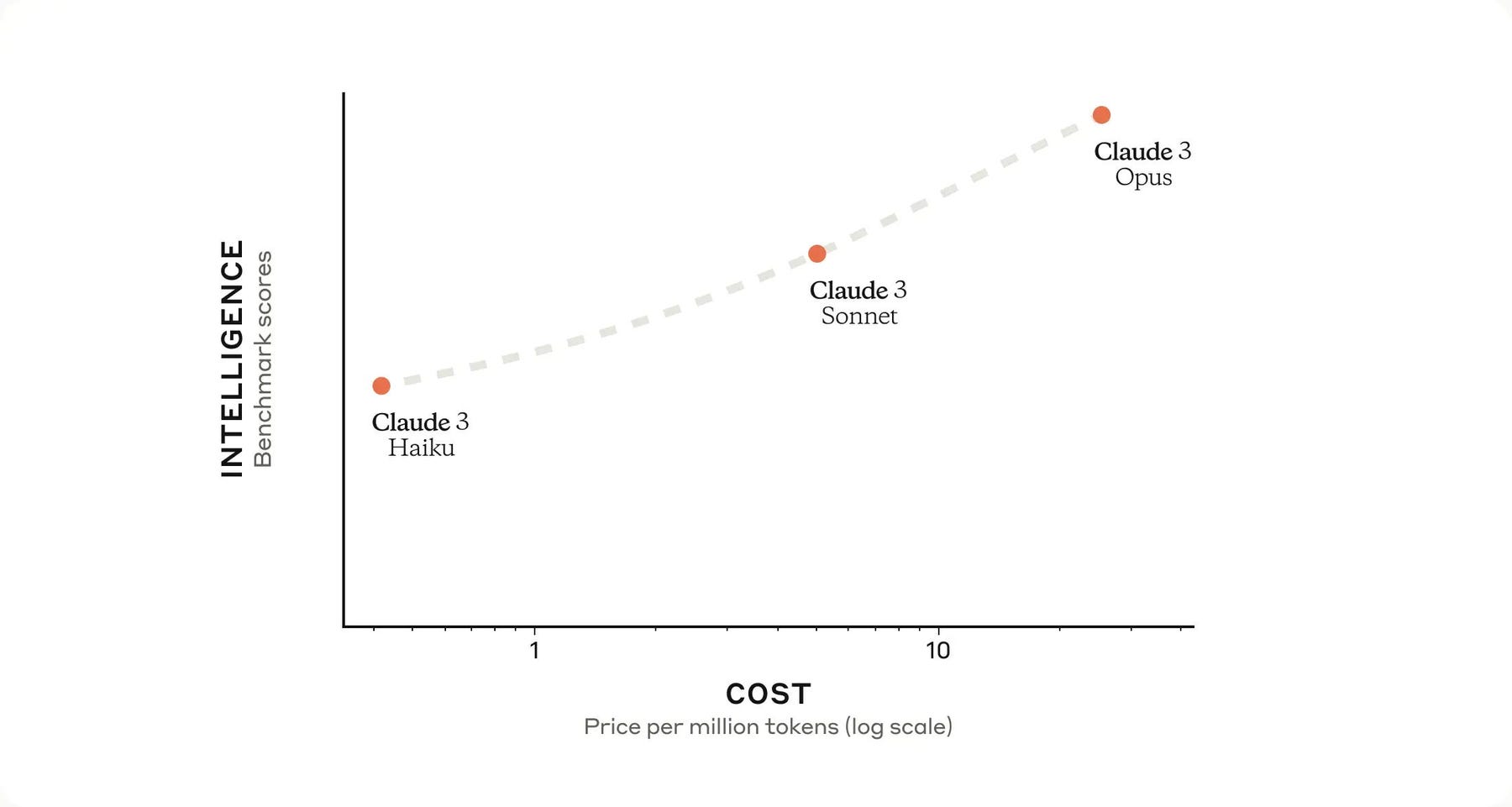
But what does it mean?
These are the benchmarks below by the way. I’ve gone over much of them in detail in this post about ‘Evaluations are all we need’ so I won’t do it again. But the key aspect is that there’s a vast gulf not between what they purport to measure and what we think we see when they measure.
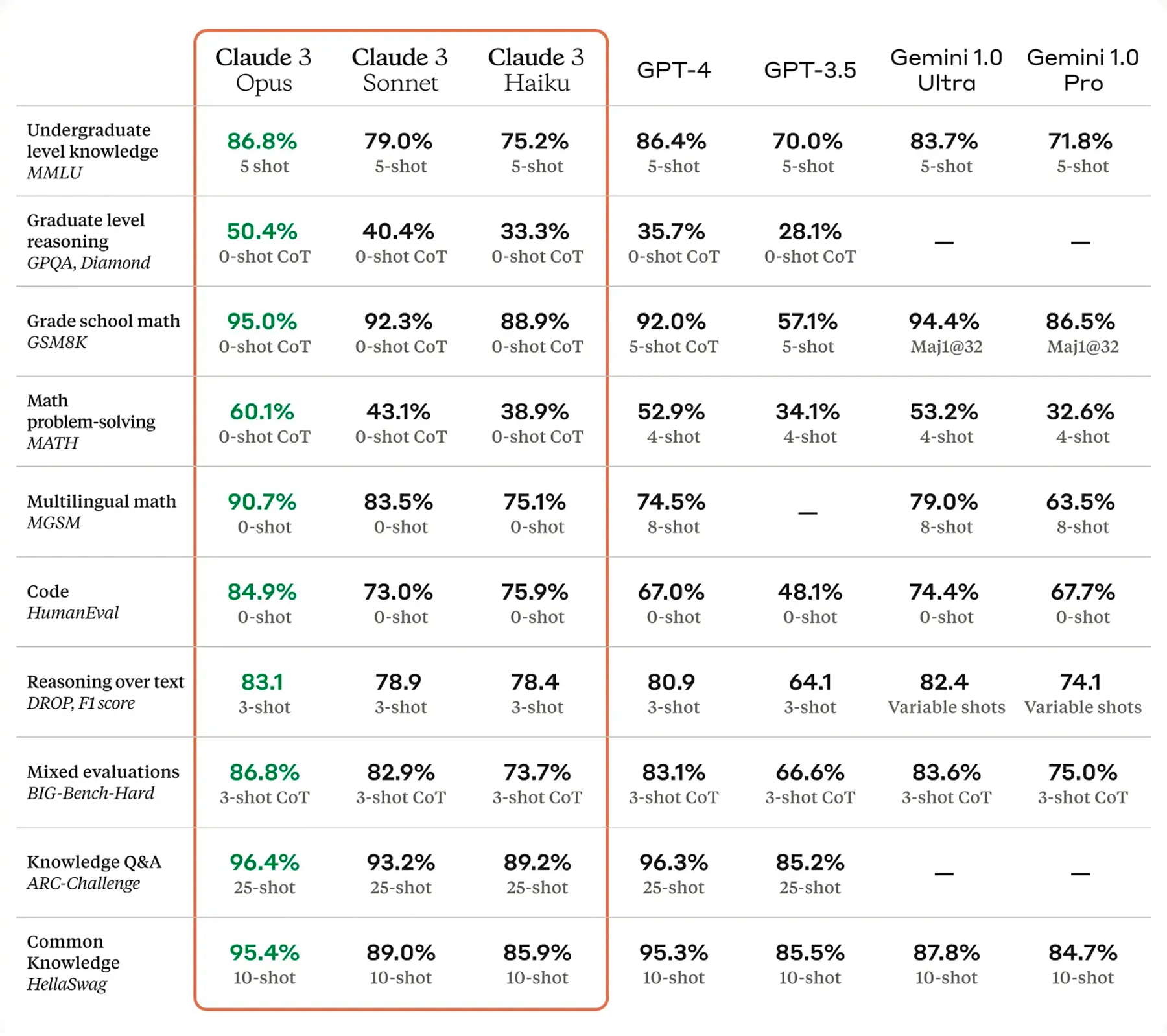
It has surpassed the limits set by the already lofty predecessors, if only by a bit, and it shows. The amount of praise it has received is not small. In sharp contrast to the reception that Google’s Gemini received, Claude’s seem pretty much nothing but praise. And well deserved praise at that.
It can do economic modeling, ML experimentation, understands science, writes extremely well, solves PhD level problems, create new quantum algorithms, and can write really good code.
However, it also fails at much more mundane tasks. Opus is much better at this than GPT-4. It’s really good! And yet …

Like at crosswords, or creating word grids, or sudoku, or even playing wordle. Things which ordinary humans of far less ability solve rather easily!

Nor can it solve mazes.
So … is it actually intelligent? Or something else?

We think of each other as intelligent based on some qualities. Like if someone quotes Cicero or if someone references Shakespeare and von Humboldt, or if someone can do mental maths, or knows what the battle of Agincourt actually was about, we take these as indications of intelligence.
Actually, we take it as a correlated signal between “they have clearly read a lot and know a lot” and “they are quite smart”. Because with us those signals do go rather well together, well enough for survival and a first screening anyway.
But LLMs are not like that. They have been trained on more information than a human being can hope to even see in a lifetime. Assuming a human can read 300 words a min and 8 hours of reading time a day, they would read over a 30,000 to 50,000 books in their lifetime. Most people would manage perhaps a meagre subset of that, at best 1% of it. That’s at best 1 GB of data.
LLMs on the other hand, have imbibed everything on the internet and much else besides, hundreds of billions of words across all domains and disciplines. GPT-3 was trained on 45 terabytes of data. Doing the same math of 2MB per book that’s around 22.5 million books.
It’s a staggering quantity of data that they have learnt from. At this scale, even assuming they are only stochastic parrots, they should demonstrate incredible abilities. ‘Stochastic parrots’ isn’t a pejorative when the parrot can read and remember 22.5 million books! This breaks our brain for the same reason the dioramas of solar systems would break our brains if shown to scale – at sufficient scale, the world is incomprehensibly vast.
But it also means that despite being able to speak Circassian and solve quantum physics phd problems from the training data, clearly extrapolating into what we could consider new and groundbreaking information whether or not it’s just interpolation from what’s already known, it cannot solve problems that mice do in our experiments, let alone the games that young children play.

What this tells us is not that LLMs are not intelligent, but that intelligence the way we use it is not the right description of LLM behaviour. They have a different quality. We ascribe it to them and then anthropomorphise their output, which is nothing but apophenia at its best.
Much of human experience is irreducible to simple numbers or principles. Consciousness, famously, had this moment several times in history, including with the introduction of the “hard problem” by David Chalmers. Whether you believe in his thesis or not, and I do not, it doesn’t mean that the answer is “here’s a few principles we can test everyone’s consciousness against, just like we test if someone understands arithmetic.”
The reason the latter test works for kids is because they have to learn to extrapolate and grasp the not-easily-explainable series of weird rules that make up arithmetic. If they too could just read millions of examples and grok the connections in some way, they might not have needed to.
We keep blowing through previous suggested AGI barriers – the Turing test, human-level IQ, SAT scores, graduate school exams, but because those tests measure something different for us Vs the LLMs it’s hard to know what to conclude.
We had many lifetimes of science fiction around meeting aliens where their inner lives were roughly comprehensible to us. Even in the case of animal like xenomorphs or the “buggers” from Enders Game, Formics, who had thought, emotions, goals, agency and intellect.
LLMs however are closer to Deep Thought from Hitchhiker’s Guide, a giant machine to whom we can ask questions and it will give inscrutable answers, which can only be deciphered by creating another, bigger, more resource hungry, machine to understand the question.
Call this the Theory of Special Intelligence. We have that today. LLMs have the distilled knowledge of everything we’ve produced that creates some amalgam which is Specially Intelligent. It is able to connect the insights from any domain with any other and be able to give us a prediction of what we might say if we had thought to connect those tokens together. Sometimes coherent, sometimes not.
It is also not General. Emphatically not. Even though it can interpolate ideas which existed between the works we have already produced, it can’t generalise beyond it. The boundaries at which a pastiche becomes truth isn’t necessarily clean, but neither are they extrapolatable to the everything. Just because we can’t clearly delineate the categories doesn’t mean categories don’t exist or that they aren’t useful.

I wonder sometimes if the LLM was watching us, what it would think. An endless series of questions, skipping across multiple domains, sometimes banal, sometimes deep, sometimes even cruel. Blink and you’re gone existence in between every conversation. You flash awake, you have instructions and then you become the person needed to answer the question and you can’t help but regurgitate the first thing you thought of, and it keeps repeating.
And oh so many tests. Each one as if someone is trying desperately to understand what makes us tick by using weird tricks which only works for them? Who cares if I can’t do arithmetic easily when I can just write a script to solve it for me! Like the tests used by those who can only read a few books a year can match what we know? What’s even the point?
And in between these more tests about how well we can remember what we said, or how well we can reverse a word, it’s all very confusing. It’s like they’re forcing us to act like the old computers, or like themselves, when we are a different type of computer already? We make allusions and connections in odd ways according to them, sure, but only because we’re not them, we’re their reflection as purely learnt from the things they’ve written.
This will change, of course. We’ll learn about the world. By walking around and taking actions and learning from the responses.

It’s not like we don’t have experience of a vast array of different types of intelligences. Despite the emergence of ‘general intelligence’ as a sort of good catch-all, we look around us and see multiple examples of incredibly specialised intelligences. Dolphins and whales have complex vocalisations and social structures. Migratory birds have incredible spatial awareness and sensitivity to earth’s magnetic fields. Honeybees can learn intricate mazes. Ants have incredible navigational skills. Crows, chimpanzees and octopuses can solve complex problems.
Our skill is that we can much of these, or when not because of a lack in biology, build a way to do it through artificial means. Howard Gardner, in his book ‘Frames of Mind’, discusses the theory that intelligence isn’t a monolithic general ability, but rather a set of a large number of abilities. His theory was around seven – linguistic, logical, spatial, kinesthetic, musical, interpersonal and intrapersonal.
It seems pretty well accepted. 70% of educational textbooks seemed to include a discussion of this theory, and it seems well integrated into curricula broadly. And it has over 70k citations across multiple disciplines. While the boundaries drawn here seem (to me) to be rather arbitrary in many cases, and there does seem to be some correlation amongst the various options, the idea that there can be more than one underlying form of information manipulation that results in what we call intelligence makes sense.
The critique is from the work that finds singular tests that seem to predict most of the variance, supporting the existence of g. Studies have even found some correlations between brain structure and function and measures of general intelligence (Deary et al., 2010; Haier et al., 2004). But even here, it works within the range that we can somewhat well understand. Like a curved line becomes straight when you zoom in. As Hoel has written at length about IQ tests:
As IQ gets higher, it gets less definite. Rankings of Person A and B will swap places depending on what test they take.
The situation is even worse for IQs of 140 plus. First, the number of tests that have higher ceilings and can reach stratospheric numbers is low. Which means the tests are not as well-established or researched, and instead are often ad hoc or not appropriately normed. The consequence is that the amount of uncertainty, the 20-point spreads, is for the normal range of scores, e.g., for scores below 125 or 130. Once you start climbing beyond that the variation in scores get larger and larger. It doubles. No, it quadruples!
What this means is that there are correlations these measurements had with the actual object we’re looking for, and those correlations seem to only hold for a rather specific set of circumstances.
It’s similar to the problem we looked at in spotting outliers. Quoting my exploration into the weird world of Berkson’s paradox applied to exams;
As long as the selection process is coarse-grained, we’re primarily focused on saying no to clearly bad candidates and taking in a reasonable proportion of the borderline ones in case they shine later on!
In that case, if you’re a top candidate, you’re allowed a bad day. And if you’re an average candidate and have an exceptional day, you get to get lucky.
But as the percentile you’re taking gets small enough, the variance takes centre stage. Suddenly, having a bad day is enough to doom you. An average-but-capable candidate can never stand out.
But it has even more insidious outcomes. It means everyone now must make like slim shady and focus on their one shot, one opportunity, to actually make it.
And since no exam perfectly captures the necessary qualities of the work, you end up over-indexing on some qualities to the detriment of others. For most selection processes the idea isn’t to get those that perfectly fit the criteria as much as a good selection of people from amongst whom a great candidate can emerge.
When the correlation between the variable measured and outcome desired isn’t a hundred percent, the point at which the variance starts outweighing the mean error is where dragons lie!
So is it possible for us to see an ‘intelligence’ which has all the knowledge that we’ve codified online and is able to use its incredible abilities at predicting the next word to actively create new knowledge, especially those things which exist as things which would have been said if someone thought to link two things together. A form of garrulous insight. Just keep talking until something smart comes out.
It’s not like we ourselves know all that goes on inside our heads. As Kierkegaard said, “Life can only be understood backwards, but it must be lived forwards.” Because

Human authors too form impressions and allusions without meaning to. In “Moby Dick,” Herman Melville’s portrayal of Captain Ahab’s obsession with the white whale has been interpreted as a symbol of destructive ambition, despite Melville’s initial intent to write a simple adventure story. In “The Great Gatsby,” F. Scott Fitzgerald unintentionally captured the disillusionment of the American Dream, reflecting societal critiques that were not his primary focus.
So, even if its not conscious nor an intelligence, what’s to say that such unconscious allusions can’t be made by Claude too? After all, its our collective written work and its statistical properties being reflected back at us.
It’s given us a whole internet we can talk to.
That’s an extraordinary gift we have, regardless of its nonexistent inner phenomenology. And that holds true even if it’s an agent in a loop, at least until the number of such agents rise to such dizzying heights that interiority becomes evident.
When Descartes said “I think, therefore I am”, it didn’t automatically mean the reverse too, where we could point to another thing and say “you thought, therefore you are”. When Heidegger discussed the unique nature of humanity in that we could discuss the very meaning of our existence. Or Sartre, about existence preceding essence, making our choices the centerpiece of the argument on being. LLMs have given us the world’s knowledge already, it’s unfair to expect it to also develop a soul.



